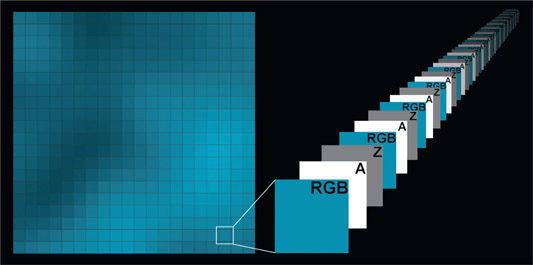
7.1 Multi-pass CGI Compositing
Rendering CGI is very expensive (meaning compute time here). A sophisticated CGI character can take as long as 24 hours PER FRAME to render. The entire strategy to compositing CGI is based on this crippling rendering bottleneck by moving as much of the workload to compositing as possible. The basic idea is to not only render each object separately but to also render each object in separate lighting passes. The compositor then combines the lighting passes to build up each character, then each character is composited individually in the scene. The huge win here is that if a change is needed (and changes are always needed) rather than firing up the render farm for a week to, for example, increase the specular highlights, the compositor re-comps the shot with the highlights dialed up – in a few minutes.
In fact, the CGI compositing pipeline is evolving to the point where CGI artists often just blast out the lighting passes without fussing over them with repeated re-rendering, then give them to the compositors to dial them in for the finished look during the comp. We like this because it has dramatically increased the contribution and importance of the compositor to the final look of the shot to such a degree that in some corners the job is now referred to as a Lighter/Compositor. Of course, to do this you must first master multi-pass CGI compositing.
Besides the production efficiency of rendering separate layers there is also a huge work-flow advantage. Most of the CGI we composite is over live action. Separating out all of the objects and lighting passes allows for some compositing magic to be applied to the finished scene item-by-item that could not otherwise be done if all objects were rendered as a single image. Besides the obvious issue of color correcting each object individually, other examples would be adding glows, interactive lighting effects, shadow effects, depth haze, depth of field, and many, many other effects that are added during compositing.
7.1.1 Process Verification for Your Renderer
You may have heard many things from many sources about the proper math operators to use for various types of lighting passes. Some say screen, others say multiply, I will say add (sum) in this book. But who to believe? Me, of course, but I offer you an empirical method for determining exactly what is correct for your particular workflow – a process verification for your renderer whether it is RenderMan, Arnold, V-Ray, Mental Ray, Arnold, or any other.
Here’s the idea – when you combine all of the separate passes for a CGI object it should match exactly the same object rendered in its entirety with all passes combined inside the renderer. This criteria cannot be disputed. All CGI renderers work internally in linear float, so obviously your compositing must also be linear float. But what about the math operations to combine the various passes?
Have the CGI department do a “hero” render of an object with all of the lighting passes combined inside the renderer – ambient, diffuse, specular, reflection, ambient occlusion, etc. This can be a single frame. Then you combine all of the separate passes for the same object and compare it to the hero render. They should match exactly. Forget what you have heard. This is the definitive proof that you have a correct workflow.

Figure 7.1
Multiple render passes combined into a composite (Space fighter courtesy Tom Vincze)
7.1.2 Render Passes
Rendering in passes refers to rendering the different surface attributes of a CGI object into separate files so they can be combined in compositing. A CGI object’s appearance is built up with layers of different materials that combine to give it its final look. In so doing the compositor can make adjustments to each layer to control the final look without having to re-render the CGI. If the reflections need to be increased the compositor simply dials up the reflection layer in the composite. The CGI is not re-rendered unless a change is need that is beyond what can be adjusted in compositing. Even then only the render pass in question is re-rendered, not the whole lot.
Figure 7.1 shows just some types of render passes that might be used for the final composite. These are not the only passes and indeed other types of passes could have been created. There is no industry standard list that is always used, and in fact, render passes can be created that are unique to a specific shot. In this example a Luminance pass was needed for the glowing parts of the laser cannon tips and hot engine parts, which would not be needed if rendering non-glowing objects.
There are a great many possible types of render passes, and the breakdown for which passes are needed will vary from shot to shot. However, many vfx studios have their own standard list of render passes that they always output for every shot. If a shot does not need to use a particular pass then the compositor simply ignores it. Particular shots may need some special passes to accomplish some particular effect, so those passes will be added to the standard render list. You might composite one shot using only five passes while the next shot will require 20.
Here are some commonly used render passes and what operation to use to layer them together. There are no industry standards on the types of render passes or their names so there are many religious differences on these points. Be prepared to go with the flow of whatever visual effects studio you are working for. But here are some common ones:
Beauty pass / color pass / diffuse pass – is a full color render of the object with colored texture maps and lighting. It will normally not include the specular highlights, shadows, or reflections, which will be rendered in separate passes then blended with the beauty pass in comp.
Specular pass / highlight pass – all other attributes are turned off and only the specular highlights are rendered. This pass is summed (added) to the beauty pass.
Reflection pass – all other attributes are turned off and only the reflections are rendered. This pass is summed (added) to the beauty pass.
Ambient occlusion – an all-white version of the object with dark regions that is essentially a map of how the ambient light diminishes in corners, cracks, nooks and crannies. It is not a color pass representing light, so it is applied with a multiply operation.
Shadow pass – often rendered as a one-channel image as a white shadow over a black background. This is typically used as a mask for a color correction operation that introduces the shadow to the comp, as well as imparting a color shade to it.
Alpha pass – the alpha channel for the object that carries the transparency information about it and is often rendered as a separate one-channel image, white over black.
7.1.3 Lighting Passes
Lighting passes render each light (or group of lights) separately for each render pass so that the light levels can be dialed in at comp time to provide even more control over the final comp without re-rendering the CGI. This is particularly important when compositing CGI with live action, where the lighting must carefully match the live action scene, plus the frequent need to animate the lighting to respond to changes in the live action. Lighting effects driven by the live action are much easier to animate in 2D than in 3D.
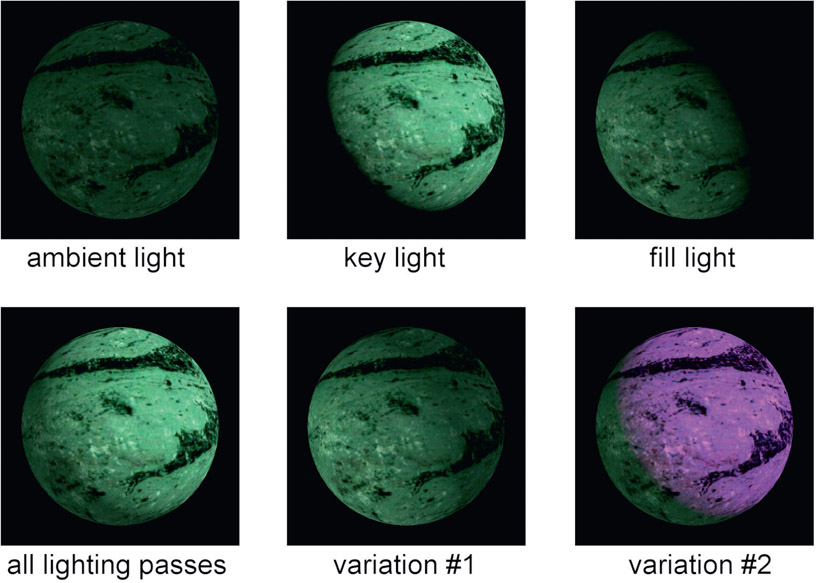
Figure 7.2
Multiple lighting passes composited together
Figure 7.2 shows a simple CGI object rendered with just an ambient light, fill light and a key light. The initial comp of all the lighting passes is shown in the lower left image (all lighting passes). Now, variations of the lighting become very cheap and easy to do with no re-rendering of CGI. In variation #1 the main lighting direction was totally reversed simply by raising the fill light and lowering the key light, and in variation #2 the key light was colored magenta. The point here is that massive changes in the lighting can be made in seconds in comp rather than days in render.
WWW Lighting Passes – this folder contains the three lighting passes from Figure 7.2 that you can comp in your own software with the plus operation. Try some lighting variations of your own.
7.1.3.1 Render Passes Workflow
There are two basic workflows to compositing CGI. The first I call a “bottom up” approach – all of the separate render passes are combined to build up the character from scratch while each pass is individually dialed in for the final look. The second I call a “top down” approach – starting with the beauty pass, other passes such as specular and reflection are then added to it. If a revision to a pass is needed that is already baked into the beauty pass then that pass is backed out, modified and then merged back in. Here are the basic rules:
- If the render pass represents light (ambient, diffuse, etc.) then it is added (summed) to build up the light layers.
- If the render pass is lighting information (ambient occlusion, etc.) then it is multiplied.
- If the render pass is a shadow then it is used as a mask to color correct the background to impart both shadow density and color.
- If the render pass is an AOV then it is used to modify the composited CGI in some way and its use is totally dependent on what kind of information it holds.
The following example illustrates the “bottom up” workflow for building up a CGI composite by combining all of the render passes for the final comp. It includes which math operators are used for combining common render passes.
WWW Render Passes Workflow – this folder contains the five render passes from Figure 7.3 that you can comp in your own software using the math operations as described.
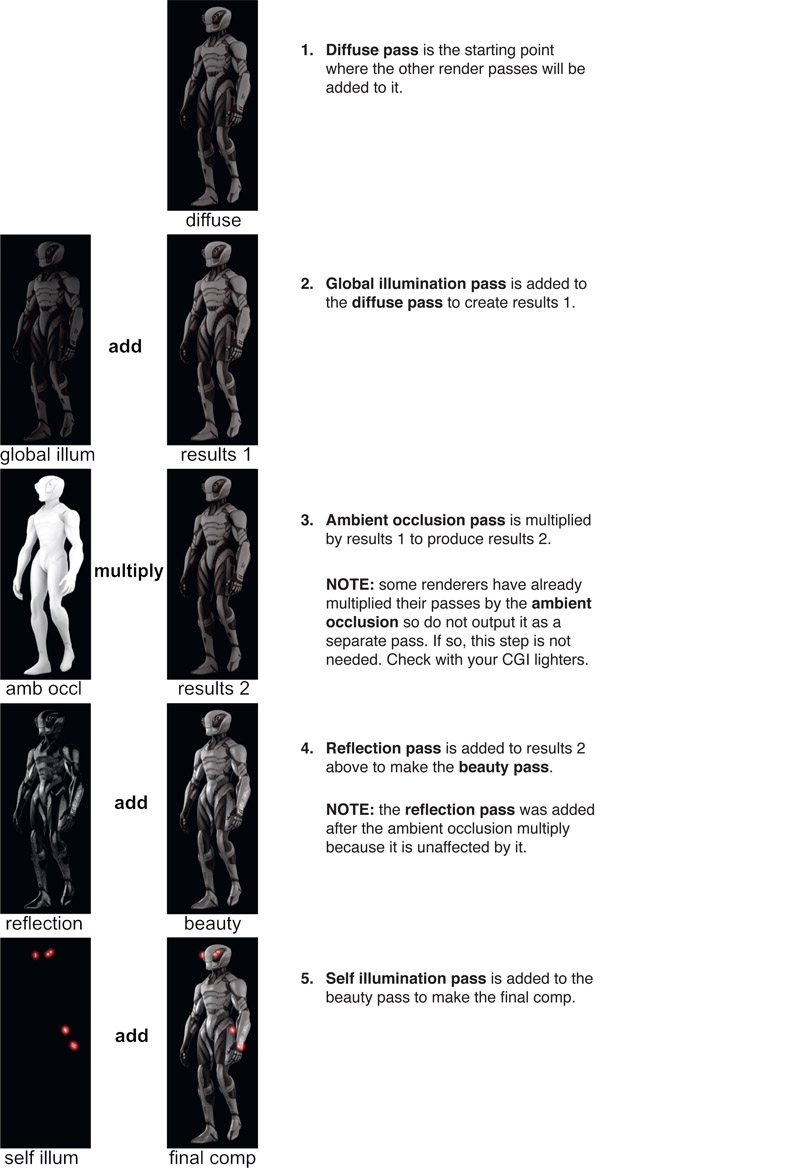
Figure 7.3 Render passes workflow (Mantis model provided by CG Spectrum)
7.1.3.2 Beauty Pass Workflow
This illustrates the “top down” workflow starting with a beauty pass. You might think that starting with the beauty pass, which is already a combination of multiple render passes, might be restrictive because the passes are baked in. Not a problem. If, for example, the diffuse lighting needed to be lowered or colored red, it can be subtracted from the beauty pass to back it out completely, then color corrected and added back in.
Here is a workflow example that starts with the beauty pass then the reflection pass is backed out, color corrected to a deep blue, then added back in:

Figure 7.4
Beauty pass workflow
WWW Beauty Pass Workflow – this folder contains the three render passes from Figure 7.4 that you can comp in your own software using the math operations as described.
7.1.4 AOVs
AOVs (Arbitrary Output Variables) are also render passes, but these passes contain data about the scene, not color or light information. A common example would be the depth pass which, for each pixel, contains the distance from the rendering camera imaging plane to the surface of the object. It looks like a grayscale image, but the code values of each pixel represent distances, not color. Again, this AOV is information about the scene, not the scene itself.

Figure 7.5
Depth of field added to a 3D image using a depth pass
Like many AOVs, the depth pass can be used to add a variety of effects. It might be used to introduce a depth haze to a shot, to control the falloff of a lighting effect with distance, or to control a depth-of-field blur on a 3D object like the example in Figure 7.5. The depth pass contains the depth information, but to use it a tool must be used that understands the meaning of the data and knows how to manipulate the image that the effect is applied to – so we will need a DepthBlur operation. Figure 7.5 shows a depth blur applied to the original render. Note that a depth blur is different than a regular blur. Such distinctions are clarified in Chapter 11: Camera Effects.
Tragically, there is no industry standard yet for the data format for depth information, or for any AOVs for that matter. One rendering software package might define zero black to be infinity and the code values get larger (brighter) as the surface gets closer to the camera. Another may make the opposite determination – where brighter is further from the camera. Perhaps this one defines the data to be absolute distance from the camera, but that one defines it as a ratio of the distance to some reference. This is particularly exciting for us compositors because we may actually be dealing with more than one renderer in a job, each with its own ideas about depth data. It’s a wild and woolly world out there so you will have to know the format of the depth data you are working with and inform your compositing software appropriately. Since the 3D coordinate system assigns Z to the depth axis into the scene, the depth data is stored in the “Z” channel like the alpha is stored in the “A” channel, so some call this “depth Z data”. Again, there are no set standards.
Another commonly used AOV pass is the motion UV pass, shown in the center panel of Figure 7.6. A motion UV pass is a two-channel image containing pixel-by-pixel data on how an object is moving. The motion data for a pixel requires two numbers – how much the object moved in X and how much in Y. The black part of the image is not missing data. It may simply mean the motion is zero (a static object) or it contains negative numbers which appear black in the image viewer. Again, our compositing program must have a tool that both understands the motion data and how to apply it to the image. The original image in Figure 7.6 had the motion UV data applied to it with a MotionBlur tool to produce the motion-blurred image on the right. Applying motion blur this way is vastly cheaper computationally than calculating true 3D motion blur in the render, and also allows it to be dialed in during the comp as well.
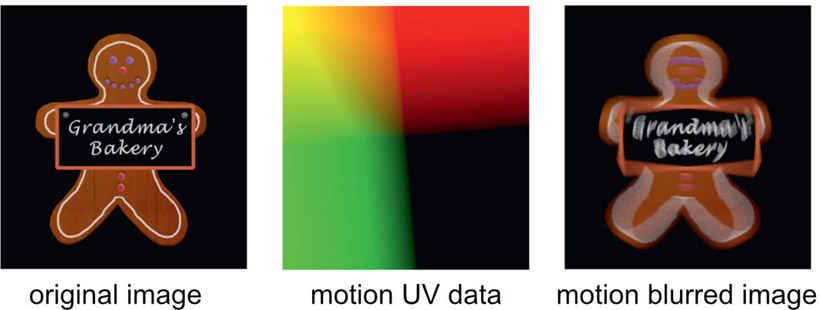
Figure 7.6
Motion blur added to a 3D image using a motion UV pass
Like the render passes and lighting passes there is not a standard list of AOV passes that you can learn about and be done with it. There are common ones like the depth Z and motion UV, but data passes can be invented for just about any special problem in production.
7.1.5 ID Passes
ID (identification) passes are masks rendered for specific items within an object that are used to isolate those items for special treatment such as color correcting. Using the car in Figure 7.7 as an example, the side windows may need to be darker and the alloy wheels more reflective. In order to isolate these parts a mask is needed, and that is what the ID passes are all about.
The idea is to give the compositor control over the final color correction of each and every part of the CGI object by providing a separate mask for them. Providing the masks is far more efficient than rendering the object in multiple pieces so each piece can be individually color corrected. Instead, a series of ID passes are rendered, but the interesting thing here is how they are stored in the image file.

Figure 7.7
CGI object rendered as a single object

Figure 7.8
Matte passes in the red, green, and blue channels

Figure 7.9
ID matte pass file #1
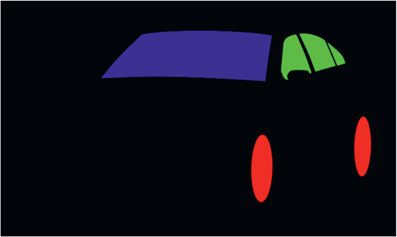
Figure 7.10
ID matte pass file #2
Rather than creating a separate file for each mask it is more efficient to combine several masks into one file. Since a mask is a one-channel image and an RGB file has three channels there can be three masks in each file if one mask is placed in each of the red, green, and blue channels. RGBA files could be used to put a fourth mask in the alpha channel as well.
Figure 7.7 illustrates a CGI model rendered as a single object. Of course, as we saw above, it would actually be rendered with multiple passes. You can imagine the database disaster it would create if the car were rendered in dozens of separate pieces, each with all the different render passes. Figure 7.8 shows a total of six masks that were rendered as three masks in two different RGB files. For this reason some call these RGB masks. Not a very descriptive name if you ask me, so we won’t go there.
Figure 7.9 and Figure 7.10 show what the two ID pass image files look like when viewed individually. The beauty of this arrangement is that you get three masks in each file (four, if the alpha channel is used), the render is cheap (i.e. fast) and the file size is incredibly small. This is because the picture content is incredibly simple, being almost all either solid black or solid white data in each channel, which is very efficiently compressed by a lossless run-length encoding scheme such as LZW compression.

Figure 7.11
RGB channels separated into one-channel masks
Figure 7.11 shows the red, green, and blue channels of the ID pass from Figure 7.10 that have been separated into single channels for masking. Of course, the savvy compositor would not actually have to physically separate them into single channels like this because the mask input of an operation can usually be directed to use either the red, green, blue, or alpha channel as the mask.
WWW ID Mattes – this folder contains the car and the ID mattes from Figure 7.8. Try your hand at using them to selectively color correct different areas of the car.

Figure 7.12 An RGBCMY ID pass
Some make the mistake of trying to pack more masks into an RGB image by adding CMY masks (Cyan, Magenta, Yellow) like Figure 7.12 that are easy to isolate with a chroma key. Don’t do this. Upon close inspection you will find degraded edges where CMY masks touch or overlap RGB masks. ID masks take very little disk space because they are run-length encoded so there is little gain with this trick. Further, with the use of EXR files (coincidentally, the next section) any number of ID masks may be put in single file so there is no saving in the number of files needed either.
7.1.6 Normals Relighting
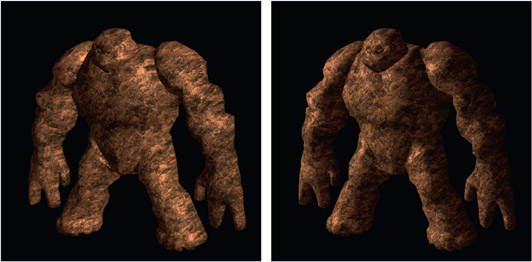
Figure 7.13
Light direction changed with normals relighting
Speaking of AOVs, here is a truly spectacular use for them – a finished CG render can actually be re-lit during compositing. Not just increase or decrease this or that lighting pass but actually pick up the light sources and move them in the scene to light the object from a completely different direction like the example in Figure 7.13. The picture on the left shows the character lit from the right side while the picture on the right shows the same image after normals relighting where the light source has been moved around to the left side. Again, this is done entirely in compositing with no 3D models or rendering. But how is this even possible when working with just 2D images?

Figure 7.14 Position and normals AOV passes
With AOVs, of course. Figure 7.14 shows the two AOVs that make the magic happen. On the left is the position pass, which is the original XYZ location in 3D space for each pixel. The AOV on the right is the normals pass, which is the direction that each surface was oriented for each pixel. What exactly surface normals are is explained in Chapter 8: 3D Compositing.
These two AOVs give the compositing software the location in 3D space of each pixel and its orientation. Add to this information the original 3D camera and light positions and the normals relighting tool can calculate how that surface would be lit. The lights in the compositing software can then be repositioned and the normals relighting tool will calculate the new lighting for the object. A CGI object that took days to render can be relit in minutes. This is a dazzling illustration of the power of the industry trend to do things in 2D rather than 3D. Does your compositing software have a normals relight tool?
As if the amazing power, flexibility and speed of AOVs were not enough, the real kicker is that they are also practically free. The reason is that the 3D rendering software has to calculate these AOVs internally anyway as part of their normal internal math operations. All we need to do is ask the 3D renderer to write them to disk instead of discarding them. To be sure there are other AOVs that can be rendered that the 3D software did not need, so they would add slightly to the rendering overhead. But the point here is given the information about the original 3D scene that AOVs represent, modern compositing software can do some amazing things. But more importantly, they can do them in seconds, not days. And in the world of visual effects, speed is life.
There is another spectacular use of AOVs where the 2D images are used to create to a 3D point cloud of the character for 3D lineup. But that will have to wait for the next chapter.