2
Formatting and structuring knowledge
Introduction
Chapter 1 was concerned with the significance of knowledge management in general terms; here we turn specifically to the organization of knowledge. After reading this chapter you will:
understand the uses of information
be aware of the need to organize information
have a plan of the principal fields within which information is organized
be aware of the traditional tools for organizing information
appreciate the different types of databases that might be important in the organization of knowledge
be aware of the need for database structures
learn how text is organized into documents
understand the formats in which documents are presented
be aware of intellectual relationships between documents
understand the forms of markup and metadata that are applied to electronic and printed documents.
Information and Its Uses
‘Knowledge’, said Samuel Johnson, ‘is of two kinds. We know a subject ourselves, or we know where we can find information upon it’ Most of this chapter, and of this book, is concerned with Dr Johnson’s second kind of knowledge. An information scientist today would define knowledge as the integration of new information into previously stored information to form a large and coherent view of a portion of reality - a definition which fits both human- and machine-held knowledge, and describes the knowledge bases used in expert systems. Information to an information scientist is a set of data matched to a particular information need. This again is valid, whether the information is stored in a computer system or in our brain. Most of the information that reaches the brain never gets beyond short-term memory: where to find the doorknob, whether the traffic lights have changed to green. Some might be useful enough to be committed to long-term memory: the price of a loaf; the time of the last bus home. We need information to enable us to make decisions, everyday decisions like when it is safe to cross the road, or decisions with far-reaching importance like whether to change our job or move house. This at its higher levels constitutes wisdom, a purely human attribute, where information, knowledge and value criteria combine over time to enable a person to make balanced judgements. At the opposite end of the scale we have data: literally, things given. Data are impersonal and not matched to an information need: a passenger on a bus may see the traffic lights change, but does not need to act on it. The data collected by a surveillance camera or hospital heart-monitoring machine may or may not be used subsequently.
Information informs our leisure activities: we read books, pursue hobbies, talk to friends, join clubs and societies, all the while picking up and exchanging information. Sometimes information becomes an end in itself, as with the obsessive collector or the earnest-faced members of a pub quiz team. We read newspapers and watch news and current affairs programmes to keep ourselves informed about the wider community. We use information in education - our own and our children’s. With academics and other researchers, it can be said that the generation of information is their business. More generally though, information is everybody’s professional stock-in-trade. Information is the knowledge that we either know or have access to; professional skill is knowing how to apply that information. These may be the executive skills of the head of a business - or of a nation-state, or the persuasive skills of the barrister, or the diagnostic and remedial skills of the physician, or the practised manual dexterity of the surgeon, or plasterer or French polisher.
To sum up, then, these examples illustrate how our definition of information can include all the perspectives suggested in Chapter 1: as news, subjective knowledge, useful data, a resource, a commodity and a constitutive force in society. They also suggest some of the major purposes of information, namely:
decision-making
problem-solving
communication and interpersonal relationships
learning
entertainment and leisure
citizenship
business and professional effectiveness.
Knowledge, Information and Data
The data that are the raw material of information may often be generated with a minimum of human participation, as with the transaction logging of the supermarket cashier or the video-recording of the surveillance camera. There are also established research techniques - such as observation, surveys, interviews - for collecting information. In everyday life, we obtain our information from a wide range of sources. For many, the mass media - television, radio, press - are their principal sources. In Western societies, whether or not a person reads the press, there are many other printed sources, such as advertisements, instructions and other ephemera, and books. Electronic sources are supplementing, and in some cases supplanting, traditional printed sources. People are also a major source of information. Informal networks - friends, colleagues, business or professional acquaintances - are often the first resort in gathering information. Internet discussion groups are a new development of informal networking. Networks can also be formal: people who share a common interest often form organizations, which may be consulted in their area of specialization. Indeed, organizations comprise a final category of information source. Organizations generate information primarily to serve the needs of the organization, whether it be a business, a government department, an academic institution, a professional body, a political party, etc. An organization’s information is not personal to individuals acting in a private capacity, nor (with few exceptions) is it published for all to see.
Broadly, then, we can categorize our sources of information into personal, Published and organizational sources. Personal information sources include personal observation and enquiry, and our use of informal networks. Published sources include the media, books, journals, directories, the World Wide Web, etc. Organizational sources include information relating to our employment and the information generated by public, private and voluntary organizations primarily for their own use. All these sources are primary sources of information. To back them up, a huge range of secondary sources has grown up; not information as such, but tools for organizing information. It is these that we must now consider.
Tools for Organizing Information
What happens to information? The greater part by far of information stored in the brain is discarded after immediate use. The time of day is important only for planning some subsequent action; the phase of a set of traffic lights serves only the immediate purpose of crossing the road or proceeding across a junction. We do not record this information, or give it house room in our long-term memory. Some background information we do retain in long-term memory because we need to use it frequently: how to tell the time, or to proceed on green - this is part of our personal knowledge base. In between, there is information that we may possibly need to reuse at some future date or time, and this we record in personal information files. At their most basic, these files may be notes scribbled on the backs of envelopes, but most of us maintain more sophisticated databases: diaries, address books, lists of telephone numbers, sometimes commonplace books and Filofaxes and electronic personal organizers or, in the case of researchers, personal databases of documentary sources. Everybody needs to organize their own information sources. There is no single way of doing this - each of us structures our information to suit ourselves. Figure 2.1 shows one such construct.
All this is without doubt excellent advice; but once we move outside the area of personal and domestic information and into published and organizational information, the pattern changes. The information we use in our professional lives - indeed, in all contexts outside the home - has a corporate existence. Many others besides ourselves may need to access it. We will be accessing information that others have created or organized. The organization of information in professional, academic and research contexts is complex and highly formalized.
In this work we are concerned with the organization of knowledge and information retrieval in these specific contexts. In particular we are concerned with those techniques that are of interest to information professionals. These will include techniques and tools found and used in libraries, as well as other approaches used in the management of information in organizations. However, one important feature to note about such systems is that some of them do not, in fact, organize or retrieve information. Some are actually concerned with the organization and retrieval of documents or references to documents.
Conventionally, librarians have concentrated on documents and resources that have been generated elsewhere and bought in, whereas information managers have specialized in the records or files that an organization generates internally: letters, leaflets, personnel documents and a host of other items. Even this distinction is no longer clear-cut. What is clear, however, is that resources of all kinds, irrespective of their source, need organizing so that their contents can be retrieved when required. If we need our personal organizers and other devices to store and retrieve our personal, professional and domestic information, how much more true is this of libraries and organizations of all kinds?

Figure 2.1 Found on the Web: one person’s way of organizing everyday information
Fields in the Organization of Knowledge
There are now four fields in the organization of knowledge which have had separate lines of development but are now moving closer together. All can profitably make use of the tools of the organization of knowledge. These fields are:
catalogues and bibliographies, which are used by librarians to list the documents in a collection or within a specified field
indexing and abstracting services, which are used by information scientists to identify the documents that are required to meet a specific subject request
records management systems, which are the responsibility of records managers and archivists to maintain an orderly collection of records
networked resources, and in particular the Internet and World Wide Web, whose organization is to all intents and purposes a free-for-all of competing search engines and directories.
These categories are intended to represent stereotypes, and as such describe extremes. All share some common goals; but to take the issue of standards, only in the cataloguing world are standards for the creation and categorization of records widely applied. Standards exist in abstracting and indexing services and in the museum, archives and records management world, but are less widely followed. In the heady world of the Internet, the problems have been identified and there are moves towards defining standards, but the whole ethos of the Internet is so anarchic that it would be a brave person who could predict the imposition of any kind of order.
Approaches to Retrieval: The Human Perspective
In any of these environments, the objective of the organization of knowledge is the successful subsequent retrieval. Different people may wish to retrieve a document or unit of information for different reasons, and may therefore approach the retrieval process in different ways. A fundamental difference in searching strategy is between known-item searching and browsing.
Known-item searching is performed by users when they know what they are looking for and usually possess some clue or characteristic by which they can identify the item, such as its author or all or part of its title.
Subject searching is performed by users who do not have a specific item in mind. This approach does not provide positive identification: it can, in A. C. Foskett’s phrase, only ‘optimise our responses to requests for information on subjects’ (Foskett, 1982, p. 8). We call it the subject approach, though in practice all manner of other considerations come into play, such as literary form, level of difficulty, the author’s viewpoint, whether designed for continuous reading, among others. Browsing describes the situation when users have a less precise view of the information or documents that may be available or are not sure whether their requirements can be met. It is often used for the activity of scanning through a number of documents in order to refine the user’s requirements. Surfing is its Web equivalent - though this includes browsing with no purpose other than to revel in the sheer range and diversity of available resources.
There are a number of types of subject information need. A common one is for a specific item of information: the searcher knows what information is required, but is less certain where to look for it Another very common situation is for one or more documents to be required, but less than the total available. Less frequently a comprehensive (exhaustive) search may be required when it is important not to overlook any significant piece of information. This kind of information need is often encountered in the early stages of research to avoid duplicating research that has already taken place. What is common to all these types of subject information need is that they are retrospective: the searcher is looking backwards over available resources. A quite different kind of subject need is for current awareness: the need for professionals, academics and keen amateurs to keep abreast of developments within their areas of interest
Irrespective of the type of information need, there are from the point of view of the information professional two methods of conducting a search. The first kind of search is user-conducted: the documents or resources are set out in such a way that users can retrieve information for themselves. Information that is obtained in this way is said to be heuristic: users can modify their search requirements as they go along. The second kind uses an information professional as an intermediary to carry out the search on behalf of the end-user. If the user is present when the search is taking place, this kind of search may also be heuristic. If not, the search is iterative: if the search results do not adequately match the end-user’s requirements, the search has to be started again from scratch.
Approaches to Retrieval: The Machine Perspective
Here we examine approaches to retrieval from the point of view of the way information is processed. Overwhelmingly, the commonest approach is by linking words. Words in a query are matched against words in documents. This approach is implicit throughout this book. But it is not the only approach. Other approaches include:
Citation indexing. This makes use of the citations (references) appearing at the end of many documents, particularly research papers. Effectively, the author of a paper has established a link between the paper and those earlier documents that are cited at the end. A citation index makes a separate record for each cited document. Documents in the citation index are linked to a separate file (source index) of their source documents. Searching begins with a document known to be relevant, and it is possible to check either which later documents have cited it or which earlier documents it cites. Searches can be recycled backwards and forwards to build up a file of promising-looking citations.
Hypertext links are closely identified with the World Wide Web, even though their history goes back to the 1960s and they have many other applications. A hypertext link consists of an identifier - a highlighted word or phrase in a passage of text or a button to be clicked with the mouse - and a pointer that links to a related document or to another part of the same document. The user can choose whether or not to break the flow of a document by clicking a link. Souls who get carried away with this activity are said to be surfing the Web.
Information filtering is one name given to techniques for pre-sorting large volumes of data in response to a given search in order to eliminate the least relevant The search proper then takes place on a subset of the database. Another name for this is data mining.
Image and sound processing is still in its infancy. Much research is taking place into techniques for directly retrieving images, video and sound, but most working systems still rely on the use of words.
The Traditional Tools of Information Retrieval
Traditionally, the tools of information retrieval have been catalogues, bibliographies and printed indexes. These can be defined as follows:
A catalogue is a list of the materials or items in a library, with entries representing the items arranged in either alphabetical order or some systematic order. Many catalogues today are held as computer databases, when they are known as OPACs. Other catalogues are held as card catalogues, or in microform.
A bibliography is a list of items, originally books, but a broader definition is widely accepted as not confined to one collection but restricted in some other way. A bibliography may list the materials published in one country, or in a given form, or between certain dates, or a combination of these or other factors. Bibliographies may be held in the same formats and arrangements as catalogues. Like catalogues, too, the entries in a bibliography represent items, and because the layout of an entry in a bibliography is very similar to that in a catalogue, bibliographic is used interchangeably to describe either.
An index is an alphabetically arranged list of pointers guiding the user to entries in a catalogue or bibliography, or to specific places in the text of a document. The pointers, or index entries, are derived from the items contained in the collection.
A database is a collection of similar records, with relationships between the records.
A file is a collection of letters, documents or other resources dealing with one organization, person, area or subject Files may hold paper documents or be computer based.
All the above are the traditional tools for organizing knowledge. Catalogues and bibliographies are databases. The whole concept of the database is central to the structuring of information, and will be discussed further in the next section.
Databases
Library and information managers have always compiled files of information, in the form of catalogues, and lists of borrowers. Early computer-based systems in many businesses held master files typically containing data relating to payroll, sales, purchase and inventory. Such applications comprise a series of related and similarly formatted records. External databases may be accessed through the online hosts or acquired on CD-ROM or through the Internet. The information manager may download sections of these databases, with appropriate licensing arrangements, to integrate into local databases. Since databases are central to the way in which data is stored and retrieved, it is important for the information manager to be aware of the types of database that are available, any standard record formats that are likely to be encountered and approaches to database structure.
Databases may be stored on magnetic or optical media such as discs, and accessed either locally or remotely. This may include access to an organization’s database covering transactions and financial records or other databases that might be accessed remotely. Some of these databases will hold publicly accessible information, such as abstracting and indexing databases, full text of reports, encyclopaedias and directories, while others will be databases that are shared within an organization or group of organizations.
Databases that might be available to information users in the public arena and which might be access remotely via an online search service or, more locally, on CD-ROM can be categorized into either reference or source databases.
Reference Databases
Reference databases refer or point the user to another source such as a document, an organization or an individual for additional information, or for the full text of a document. They include:
Bibliographic databases, which include citations or bibliographic references, and sometimes abstracts of literature. They tell the user what has been written and in which source (e.g. journal title, conference proceedings) it can be located and, if they provide abstracts, will summarize the original document. Figure 2.2 shows part of a bibliographic database.
Catalogue databases, which show the stock of a given library or library network. Typically, such databases list which monographs, journal titles and other items the library has in stock, but do not give much information on the contents of these documents. Catalogue databases are a special type of bibliographic database, but since their orientation is rather different from that of the other bibliographic databases, they are worth identifying as a separate category. Figures 2.3, 2.4, 2.5 and 2.6 show a search conducted on a catalogue database.

Figure 2.2 Bibliographic database (Abstracts in new technology and engineering)

Figure 2.3 Catalogue database. 1: OPAC search screen

Figure 2.4 Catalogue database. 2: Search menu (help screen)
Referral databases, which offer references to information or data such as the names and addresses of organizations, and other directory-type data. Records from a referral database are shown in Figure 2.7.

Figure 2.5 Catalogue database. 3: OPAC subject search
Source databases contain the original source data, and are one type of electronic document. After successful consultation of a source database the user should have the information that is required and should not need to seek information in an original source (as is the case with reference databases). Data are available in machine-readable form instead of, or as well as, printed form. Source databases can be grouped according to their content:
numeric databases, which contain numerical data of various kinds, including statistics and survey data
full-text databases of newspaper items, technical specifications and software
text-numeric databases, which contain a mixture of textual and numeric data (such as company annual reports) and handbook data
multimedia databases, which include information stored in a mixture of different types of media, including, for example, sound, video, pictures, text and animation. Figure 2.8 shows part of such a database.
Bibliographic databases contain a series of linked bibliographic records (described in Chapter 3). Even though a number of the large bibliographic databases have been available in machine-readable form for more than 20 years, the basic elements in the database still have their roots in the printed product, which was often an abstracting or indexing tool with which they are associated. These databases were often originally constructed to aid in the more efficient generation of a printed abstracting or indexing service, and a print product often still accounts for a significant component of the database producer’s revenue. One of the benefits of maintaining records in a machine-readable format is the opportunity to generate a series of different products for different market-places from the one set of records. These products often include current awareness services, online search services, licensing for downloading sections of databases, printed abstracting and indexing services.

Figure 2.6 Catalogue database. 4: Search results

Source databases are electronic documents. Many such databases take advantage of the fact that they are not constrained by the same physical limitations as print, and are multimedia, embracing, in addition to text and numeric data, computer software, images, sound, maps and charts. These databases can be accessed online through the online search services, or on CD-ROM or via videotext and teletext or through the Internet.
Figure 2.8 Multimedia source database (Encarta encyclopedia)
Source databases are so varied in their nature and origins that it is difficult to make generalizations. Earlier in this chapter we divided source databases into numeric, full-text and text-numeric. We might also consider referral databases in this context. Although these are categorized as reference databases in the sense that they offer a pointer to further information, they are often also source databases in that they might contain the full text of a directory that could be regarded as a source document. Source databases, then, may include the full text of journal articles, newsletters, newswires, dictionaries, directories and other source materials. Many, although not all, source databases have a print equivalent Some source databases do not contain the complete contents of the print equivalent but only offer selected coverage.
Database Structures: The Inverted File
The crudest way to search a database is to go through it record by record looking for the appropriate data element. As this is slow, alternative methods of locating specific records have been developed. The online search services and other applications that use document management systems have always used the inverted file approach described below. This is useful for searching complex text-based databases, where the searcher does not know the form in which the search key may have been entered in the database, and has, essentially, to guess the most appropriate form.
Transaction-processing systems, such as library management systems, travel bookings information systems, and sales and marketing information systems, may also use this approach to locate individual records within a database, but these also need a mechanism for linking a series of distinct databases together so that information can be drawn from more than one database for display on the screen or printing at one time. This requirement in transaction-processing systems has led to the development of strategies for optimizing database design.
The inverted file similar to an index. In the inverted file approach there may be two or three separate files. The two-file approach uses two files - the text or print file and the inverse or index file. The text file contains the actual records. The index file provides access to these records. The index file contains a record for each of the indexed terms from all of the records in the database, arranged in alphabetical order. Each term is accompanied by information on its frequency of occurrence in the database, the file in which it is to be located, the record in which it is entered, and possibly further location information such as the paragraph (or field) within which it is located. When a new record is added to the database, it is necessary to update the index file.
These files are used together in the search of a database. A user who is interested in performing a search on the word ‘hedges’, for instance, will enter the term at the keyboard, and the system will seek the term in the index file. If the term is not present in the index file, the system responds by indicating that there are no postings for that term. If the term is found, the user will be told how many postings, or occurrences, of the term there are in the database. To display the records, the text file location is used to locate records in the text file.
If three files are used, there is an intermediate file that allows search terms input at the keyboard to be checked quickly and the number of postings displayed on the screen. This is particularly useful with a complex search that may involve using the index file records for a number of search terms.
The above description is intended to offer a simple introduction to the basic concept of an inverted file. In practice, file structures may be more complicated, as the following examples indicate:
If it is possible to search terms in proximity to other terms (e.g. terms within two words of each other), the index file must contain information about word positions within a field for each term.
Inverted files are often created for a number of fields within a record. However, not all fields are usually indexed, because each index takes disc storage space; indexes are created for those fields that are commonly searched. Inverted files are often created for author names, title words, subject-indexing terms and author-title acronyms.
Long full-text records need to be split into paragraphs and those paragraphs must be assigned identifiers before indexing can commence. Alternatively, the positions of individual words in the file can be used as identifiers.
Database Structures: The Relational Model
In the early days of computing, business and library systems worked with a series of individual master files covering, for example, in the case of libraries, borrowers and books in stock or, in the case of many businesses, payroll, sales, and inventory. It soon became apparent that programmes for, say, circulation control in a library needed to access two or more different files, and it was appropriate to start to examine the relationships between these files. This led to the introduction of the concept of a database, and the software to manage such databases, known as database management systems (DBMS). It then became necessary to examine the optimum way to structure data or to develop data models to support specific applications.
Relational databases use one type of database structure, which has been widely adopted in database systems. In relational systems, information is held in a set of relations or tables. Rows in the tables are equivalent to records, and columns in the tables are equivalent to fields. The data in the various relations are linked through a series of keys. Figure 2.9 shows a simple example of a relation known as catalogued-book. In this relation the International Standard Book Number (ISBN) is the primary key and may be used in other relations to identify a specific book. For example, if we maintain the relation order-book the ISBN acts as a link to the order-book relation. If we wish to complete an order form with details from the order file, data for each book can be extracted from the catalogue file and printed on the order slips alongside data from the order file.
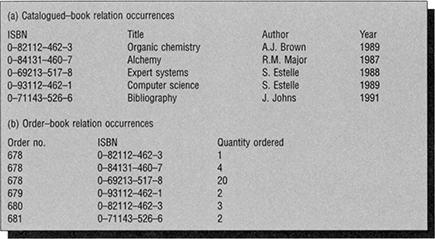
Figure 2.9 Two simple relations
Multimedia Database Structures
Multimedia databases present new challenges for database structure. Multimedia DBMSs (MM-DBMSs) are being designed to manage such databases. As pictures, animation, sound, text and data tables have very different storage needs, MM-DBMS seek to use a range of technologies, such as relational technology for tables, text databases for documents and image storage devices for graphics and animation. A central problem is the handling of non-text items such as drawings and moving images. In time varying media, access by frame is provided by digital video interactive (DVI) standards. For more sophisticated access the images have to be indexed with keywords in a similar manner to text-based documents.
Text and Multimedia
Historically, databases have been compiled from representations of documents, or document surrogates, rather than the documents themselves. It is only since the mid-1980s that it has become technically and economically feasible to store whole documents in an immediately accessible machine format, and the computer storage of graphics, sound and multimedia resources is more recent still. Many of the tools and techniques for organizing document representations have been adapted to whole documents. Others are new. The rapid growth of the Internet has produced a whole new generation of information specialists from a variety of backgrounds whose interest is in the retrieval of networked documents and other resources - whole documents and not representations of documents. We start therefore with a consideration of the formats of knowledge itself - documents and resources in their various guises - before looking at document representations in Chapter 3.
The rise of multimedia notwithstanding, text remains the basis of information. In the global society, it is worth pausing briefly to consider some of the implications of this statement. Most of the world’s languages have no written codes. On the other hand, English has effectively replaced Latin as the lingua franca of international communication. The Latin alphabet used by the English language has variants and extensions when applied to other European languages. Many Asian languages, and a few European ones, use other alphabets, and transliteration standards are needed to represent one language in the script of another. Two major languages - Japanese and Chinese - have non-alphabetic writing systems: the one is syllabic, the other logographic, each symbol representing a complete word.
The study of written languages recognizes two basic components. A language has a vocabulary of words, and a syntax: a set of rules for stringing words together to make meaningful statements. Semantics is the name given to the study of meaning in language. We will meet these terms again in Chapter 5.
The word is the unit on which many retrieval systems operate, but what is a word? Is folk-lore one word, or two? (Some retrieval systems will make three words out of it: folk, lore, folk-lore.) Most of us recognize that many words are inflected - that is, they have different inflections (endings) according to their grammatical function - but many languages take this far beyond the simple dog - dogs or bark - barks - barked - barking of the English language. Retrieval systems can easily reconcile different word endings, but sometimes languages are agglutinative - they place prefixes on to words, or string several words together to make portmanteau words. Important in German and some other languages, in English this is a problem that needs to be systematically addressed mainly in chemical information retrieval systems.
It is important to be aware of the structure of text. We - not just information professionals, but any literate person - can become more effective in understanding the gist of a document by skimming it if we have some idea how text is structured, so we know where to look and where to skip. Computers can be made to mimic human processes and apply them to text analysis. Two important structural patterns are:
Problem-Solution: at its simplest, a problem is stated and a solution proposed. A four-part variant is often found in research papers: Introduction (statement of the problem to be solved); Method; Results; discussion of Conclusions. Another variant is: statement of problem; discussion of one or more inadequate responses; and, finally, a successful response.
General-Particular, a generalization is made, and provided with one or more examples. There may be hierarchies of generalizations in that a sentence may function both as an example to a generalization and as a generalization which is itself exemplified. This hierarchical organization of text is explicit in report writing.
These structural patterns are often found in combination. Anyone used to skimming text to obtain its gist soon learns to look for cues that help to establish the subject-matter. These include elements such as section headings, or stock phrases like ‘In this paper we…’, This paper seeks to…’, and so on. Additionally, the hierarchical organization of text teaches us that the more significant parts of a text are likely to be found near the beginning of the whole document, of individual sections and of paragraphs. Not only can we learn to do these things ourselves, we can also design our search systems to act in a similar way, for example, by giving greater weight to words found near the beginning of a document.
Multimedia pose problems not encountered with text. Many non-textual collections - images, video clips, mixed media - are now held online, ranging from the large-scale digitization projects of national libraries and art galleries to personal collections, now that flatbed scanners and digital cameras can be bought quite cheaply. The types of verbal and structural cues that text offers are simply not available. Images do not even have titles, so viewers have to rely on their own conceptual interpretations. The same image can be studied at different generic levels and from a range of disciplinary viewpoints. A set of pictures of Hardwick Hall (‘more glass than wall’) in Derbyshire might be of interest to historians, architects, art historians or to someone researching the history of windows; it is an example of Elizabethan architecture, and a source of the social history of the sixteenth-century English upper classes; the National Trust (its present owner) calls it ‘a magnificent statement of the wealth and authority of its builder, Bess of Hardwick’; and its setting might be studied by landscape historians, or by a film or television producer looking for a setting for a costume drama. Faced with complexity of this order, the manual indexing of non-text media is inevitably subjective and slow. Researchers into the automatic indexing and retrieval of images by their content have an uphill struggle. Some success has been reported with systems operating on simple graphic shapes within limited domains, like engineering drawings, plant-leaf types or, operationally, fingerprints.
Documents
A document is a record of knowledge, information or data, or a creative expression. A document’s creator has recorded ideas, feelings, images, numbers or concepts in order to share them with others. Until recently, this would have been a sufficient definition. Documents were normally text based, but the definition could easily be extended to include the minority of documents which expressed themselves in some other way. Basically, stored data, in any form, constitute a document. Documents include, for example, broadcast messages and thretMlimensional objects such as models and realia. This is not a new idea: the suggestion that everyday objects could be considered to be documents goes back to the early years of this century, if not earlier: did not Shakespeare find ‘tongues in trees, books in the running brooks, Sermons in stones…? (A study in the 1950s concluded that an antelope was a document if kept in a zoo as an object of study, but not when running wild.)
Documents are traditionally perceived by the unaided eye, less commonly by touch. Formats requiring optical apparatus - slides, microforms etc. - have been with us for a long time. Electronically readable formats have a shorter history but are revolutionizing our notions of a document. Libraries have conventionally been concerned with books. Most libraries have also collected conference proceedings, reports, microforms, serials, maps, videos, slides, filmstrips and computer software; some, specializing in such media, are often described as resource centres. Libraries have always been network conscious, with their well-established and efficient networks for interlending books. More recently, libraries have begun to make use of computer networks, sometimes for housekeeping tasks like acquisitions and cataloguing, but increasingly to obtain information electronically - references to documents, actual documents, factual information, images, software, interactive media. Some people are still happy to call these documents, but it is now more conventional to use the word resources for networked resources of all kinds. The term virtual library is also used of the range of networked resources.
A recent discussion by Schamber (1996) of the definition of a document has identified some characteristics of electronic documents. They are:
easily manipulable, in that they can be cut-and-pasted, rotated, etc
internally and externally linkable, through hyperlinks
readily transformable, on to disc, print, etc.
inherently searchable, by means of search software
instantly transportable, via electronic networks
infinitely replicable, in that copying does not degrade the quality of the original.
The growth of electronic documents has given rise to some alternative notions of a document. A document can be considered in any of the following ways:
a homogeneous item: that is, a physical entity
linked heterogeneous items, e.g. the H. W. Wilson Company’s Humanities Abstracts Full Text database
a contextual display of related items, e.g. the results of a search on such a database
homogeneous items created by the user, e.g. a Web home page with its unstable set of links.
To reconcile these different perspectives, Schamber defines a document as:
a unit:
consisting of dynamic, flexible, nonlinear content
represented as a set of linked information items
stored in one or more physical media or networked sites
created and used by one or more individuals
in the facilitation of some process or project
(Schamber, 1996, p. 670)
In the context of networked resources, definitive lists of resource types and formats are being prepared by the Dublin Core (see below). There is a basic list consisting simply of these six types: text, image, data, software, sound and interactive. Greater detail is available if required. For example, image can be moving (animation, film), photograph, or graphic; sound is ambient, effect, music, narration or speech, and there are over 30 categories and subcategories of text.
While the formats of networked resources are still being formalized, the forms of presentation and arrangement of text-based documents are well established. Figure 2.10 is based on the categories found in a major classification scheme, the Bliss Bibliographic Classification (described in Chapter 8).
This is not a comprehensive listing, but simply serves to illustrate some of the more common formats. Each format has its own features and problems of indexing and retrieval. The contents of encyclopaedias and dictionaries, for example, are virtually self-indexing, and information professionals need do little more than identify them and indicate where they are located. The contents of periodicals, on the other hand, require massive and complex organization. Also, specialist areas of knowledge have their own specialized information formats. Figure 2.11 shows the formats recognized by the Educational Resources Information Center (ERIC).

Figure 2.10 Forms of presentation and arrangement in documents
Bibliographic Relationships
Documents seldom exist in isolation from one another, but draw on one another in all kinds of ways. In literary studies this is known as intertextuality, and includes a range of pursuits from the tracking down of passing allusions, to fullblown parody. Information retrieval makes use of relationships between documents in a number of ways. It is clear that, if some kind of intellectual relationship exists between two documents, a user who is interested in one may well be interested in the other also. One way is through citation indexes. These are reverse indexes to the lists of cited works that appear at the end of research and other documents, and enable searchers to see which later documents have cited an earlier one. Another way concerns cataloguers in particular, who are engaged in a reexamination of what used to be known as the bibliographic unit problem. The problem is one of identifying the overt relationships between two or more documents. Recent research has identified seven categories of relationship:
Equivalence relationships between exact copies of the same manifestation of a work. These include copies, issues, facsimiles, photocopies, and microforms.
Derivative relationships, also called horizontal relationships, are between a bibliographic item and modifications based on the same item, including variations, versions, editions, revisions, translations, adaptations, and paraphrases.

Figure 2.11 ERIC publication types
Descriptive relationships: the relationship between a work and a description, criticism, evaluation or review of that work. These include annotated editions, casebooks, commentaries, critiques, etc.
Whole-part relationships, also called vertical or hierarchical relationships, are between a component part of a work and its whole, for example, a selection from an anthology, collection or series. This may even apply to the chapters of a book, as it is sometimes more convenient to regard an electronically stored book as a coordinated collection of documents rather than as a single document
Accompanying relationships, where two works augment each other, whether equally (as with supplements) or with one subordinate to the other (as with concordances and indexes).
Sequential relationships, also called chronological relationships, where bibliographic items continue or precede one another, as with successive titles in a serial, sequels of a monograph, or parts of a series.
Shared characteristic relationships, where items not otherwise related have, coincidentally, a common author, title, subject or other characteristic used as an access point. This relationship differs from the other six in that there is no intellectual relationship between the works.
Another approach argues that a document may exist at up to four levels:
Work: an intellectual or artistic creation
Expression: the intellectual or artistic realization of a work, e.g. a translation.
Manifestation, the physical embodiment of a work: for example, an author’s manuscript, or the copies in an edition of a book, or American Standard Code for Information Interchange (ASCII) and Postscript versions of a networked resource.
Item: a single exemplar of a manifestation, for example a copy of a book.
This approach is of particular interest to cataloguers, who are finding a need for new structures that accommodate networked resources.
Text Analysis
Computers are able to process very large quantities of text. With text analysis we can automate such processes as:
extracting keywords
preparing document representations, for example, by scanning title pages of books to generate catalogue descriptions or by processing the text to generate an abstract
determining various characteristics of a text, for example, its level of reading difficulty, its authorship, its chronological place within the canon of its author’s works, or the attitudes or beliefs of its author
translating the text into another language.
There are broadly two approaches to text analysis:
Statistical analysis is based on counting the frequency of particular words in the text, together with a range of more sophisticated devices, including phrases, pairs of words or clusters of words in proximity to one another. Concept frequency is another such device, where the text is analysed to generate a thesaurus, or list of words that share some aspect of their meaning, or a semantic network of words that are to be found in association with one another.
Structural analysis, or knowledge-based analysis, scans the text for words, phrases or sentences that are in significant positions within the text. For example, for indexing purposes, section headings and figure captions; for abstracting purposes and also for indexing, the first and final paragraphs of sections, the opening sentences of paragraphs, or the positions of such cue words and phrases as ‘In this paper we’, ‘method’, ‘results show’, ‘in conclusion’. For abstracting, translation and other applications which generate sentences, the text is parsed - parsing is a word-by-word analysis of each sentence using an algorithm which gradually builds up an interpretation of the text.
Knowledge-based text processing systems - expert systems - use many forms of knowledge representation. One that is commonly found is frames, which are based on human mental processes. A frame is a receptacle for information about an entity or event. It contains slots to hold the attributes of the entity. As the text is parsed or the cues read, the slots are gradually filled in. A simple frame, which could be used for newspaper stories, is shown in Figure 2.12.
At present, text analysis seems to work best within fairly specific domains, for example news items or papers in medicine. New applications are constantly being developed. One is data mining, the processing of large numbers of documents for information that is of use to an organization.

Figure 2.12 Frame for understanding and summarizing disasters
Text Markup and Metadata
Information workers in developed countries have become accustomed in recent years to being able to use computer-based search systems to search on the full text of documents. This is a very recent development, however, and the bulk of the world’s recorded information is still to be found in documents having a print or hard-copy format that is not machine readable. The traditional way of organizing such documents has been by means of surrogate documents, consisting of records showing the principal elements - tide, author etc. - which identify and characterize the documents for retrieval. These take the form of citations in bibliographies and indexes, and catalogue entries. These are discussed further in Chapter 3. Collectively they are known as bibliographic records.
The electronic retrieval of text has led to the development of yet another tradition: metadata. Metadata (‘data about data’) describes the additional elements needed to identify and characterize an electronic document. It always accompanies the document, and to that extent corresponds, very loosely, with the preliminaries (title page, etc.) of a printed book. Functionally it has much in common with bibliographic records.
Electronic text at its most basic uses the ASCII character set. This includes all the characters found on a keyboard plus a few others. Extended ASCII character sets (256 characters) also include the diacriticals found in many European languages. (Chinese logograms are a problem apart. One encoding system has 65 536 possible characters, enough for everyday use but not for advanced work.) ASCn does not include any of the elements which define the layout of text into paragraphs etc., or its actual appearance, as for example the use of bold type or different fonts. Word-processing and publishing software have used their own codes, and this has lessened the portability of documents between systems. Also, within an organization it is often necessary to store documents for retrieval and reuse. Often only parts of a document will be reused, and selective revision and reformatting may be applied. The application of markup to plain (ASCII) text enables electronic documents to be stored and reused efficiently.

Figure 2.13 A simple SGML document
Markup is of two kinds:
Procedural markup originally denoted the handwritten instructions that would tell typesetters how to lay out text for printing. Word-processing and desktop publishing software use procedural markup in the same way. Procedural markup defines the final presentation of a document and, so, is specific to the application as, for example, when we instruct our word processor to change the font size or insert a page break.
Descriptive, or generic, markup defines the headings, content lists, paragraphs and other elements which make up the structure of a document, without reference to its appearance on the page.
Standard Generalized Markup Language (SGML) is the international standard (International Standards Organization, ISO 8879:1986) for embedding descriptive markup within a document, and thus for describing the structure of a document. Standard Generalized Markup Language formally describes the role of each piece of text, using labels enclosed within <brackets> It is a descriptive, not a procedural, markup language. It separates document structure from appearance, and so allows documents to be created that are independent of any specific hardware or software, and thus are fully portable between different systems.
A document type definition (DTD) accompanies every SGML document. The DTD describes the structure of the document by means of a set of rules (for example, ‘a chapter heading must be the first element after the start of a chapter’) which help to ensure that the structure of the document is logical and consistent. Many publishers use SGML.
Hypertext Markup Language (HTML) is a subset of SGML - formally it is an SGML document type definition - that has been specially developed for creating World Wide Web documents. As with SGML, an HTML document can be created using any text editor. There are also a number of HTML editors, some within word-processing packages, which insert the markup automatically.

Figure 2.14 A simple HTML document
Non-text resources (images, sound, video, multimedia) are especially reliant on markup, as systems which can automatically analyse sounds and images for retrieval are very much in their infancy.
Metadata
Metadata, data about data, is especially used in the context of data that refer to digital resources available across a network. Metadata differs from markup in being distinct from, rather than integrated with, the body of the resource: in the HTML example above, the metadata is included in the <head> section. So metadata is a form of document representation, but it is not a document surrogate in the way that a catalogue entry is. Metadata is linked directly to the resource, and so allows direct access to the resource.
Metadata also differs from bibliographic or cataloguing data in that the location information is held within the record in such a way as to allow direct document delivery from appropriate applications software; in other words, the records may contain detailed access information and network addresses. In addition, bibliographic records are designed for users to use both in judging relevance and making decisions about whether they wish to locate the original resource, and as a unique identifier of the resource so that a user can request the resource or document in a form that makes sense to the recipient of that request. These roles remain significant. Internet search engines (see Chapter 11) use metadata in the indexing processes that they employ to index Internet resources. Metadata needs to be able to describe remote locations and document versions. It also needs to accommodate the lack of stability of the Internet, redundant data, different perspectives on the granularity (what is a document or a resource?) of the Internet, and variable locations on a variety of different networks.
The need for some kind of bibliographic control over networked resources has become acute with the burgeoning of the WWW. There are a number of metadata formats in existence, and the current situation is volatile. Among the various formats, the Dublin Metadata Core Element Set appears to be the strongest contender for general acceptance.
Dublin Core
The Dublin Metadata Core Element Set, known simply as the Dublin Core, is a list of metadata elements originally developed at a workshop in 1995 organized by the Online Computer Library Center (OCLC, whose headquarters are in Dublin, Ohio) and the National Center for Supercomputer Applications (NCSA). The objective was to improve the indexing and bibliographic control of Internet documents by defining a set of data elements for metadata records of ‘document like objects’ - the scope was deliberately left open. The intention was to make the data element set as simple as possible, so that the developers of authoring and network publishing tools could incorporate templates for this information in their software. Authors and publishers of Internet documents could thus create their own metadata. This approach is akin to the practices of research publishing, where contributors to primary journals commonly supply their own abstracts, subject keywords, and affiliation details when submitting papers for publication. The Dublin Core does not prescribe any record structure and originally excluded details of access methods and constraints, though these have subsequendy been added. All elements are optional, and repeatable, and can be extended as required. Controlled vocabularies are also being developed for certain of the data elements, as an aid to consistency.
The data elements are:
Title: the name given to the resource by the Creator or Publisher.
Author or creator, the person or organization primarily responsible for creating the intellectual content of the resource.
Subject and keywords: keywords or phrases that describe the subject or content of the resource. The use of controlled vocabularies and formal classification schemas is encouraged.
Description: a textual description of the content of the resource, including abstracts in the case of document-like objects or content descriptions in the case of visual resources.
Publisher, the entity responsible for making the resource available in its present form, such as a publishing house, a university department, or a corporate entity.
Other contributor, an editor, transcriber, illustrator or other person or organization who has made significant intellectual contributions to the resource, but secondary to that specified in a Creator element Label.
Date: the date the resource was made available in its present form. The recommended format is an eight-digit number in the form YYYY-MM-DD.
Resource type: the category of the resource, such as home page, novel, poem, working paper, technical report, essay, dictionary. A list of approved categories is under development.
Format: the data format of the resource, used to identify the software and possibly hardware that might be needed to display or operate the resource. A list of approved categories is under development.
Resource identifier, a string or number used to uniquely identify the resource. Examples for networked resources include Uniform Resource Locators (URLs) and Uniform Resource Numbers (URNs, when implemented). Other globally unique identifiers, such as ISBNs or other formal names would also be candidates for this element in the case of offline resources.
Source: a string or number used to uniquely identify the work from which this resource was derived, if applicable. For example, the ISBN for the physical book from which the portable document format (PDF) version of a novel has been derived.
Language: the language(s) of the intellectual content of the resource.
Relation: the relationship of this resource to other resources, for example, images in a document, chapters in a book or items in a collection. Formal specification of relation is currently under development.
Coverage: the spatial and/or temporal characteristics of the resource. Formal specification of coverage is currently under development
Rights management: a link to a copyright notice, to a rights-management statement, or to a service that would provide information about terms of access to the resource. Formal specification of rights is currently under development.
Traditional Forms of Metadata Used by Indexers
While the term metadata is applied to networked resources, we should not forget that traditional printed materials have always had what is in effect their own metadata, which for books is called the preliminaries, the parts of a book that precede (and Mow) the actual text. The preuminaries are the principal source of information, both in preparing document representations and in providing the index terms used to access documents. They consist of the title, contents list, preface and introduction, and index, and the blurb on the dust jacket. Any or all of these may be of value in determining the subject.

Figure 2.15 Dublin Core metadata
Titles
Printed documents of all types have titles, almost always given by their authors. Indexes based on titles go back at least 150 years. A title is the author’s own summarization, identifier and retrieval cue. Research papers can usually be relied on to have informative titles, and editors of most primary journals issue guidelines to authors on the content of titles.
For subject searching, titles summarize the content of a document at its most basic level. Many indexes are based on keywords in titles, so it is important that titles so indexed should adequately reflect the subject content of the document. Less frequently, and mostly in the case of books, an author may feel that it is more important that the title should attract attention: Women, Fire and Dangerous Things (a study of the mental processes of categorization) and How to Hold up a Bank (a civil engineering manual) are two examples among many. Having decided on an oblique title, the author may make amends by means of an explicit subtitle (What Categories Reveal about the Mind). A few bibliographic search services provide title enrichment - the addition of a few extra keywords, or even a short annotation - to supplement titles that are perceived to be inadequate. This, however, requires the service of a human indexer with the knowledge to perceive and remedy the inadequacy; which in turn affects the cost and currency of the service.
It is virtually unknown for a published text not to have a title that has been assigned at or before publication. Non-textual media (e.g. graphic and cartographic material) may well not be furnished with titles, and similarly unpublished text - many untitled documents find their way on to the WWW.
Contents pages
Contents pages are usually to be found within books and journals. Their main purpose is to guide the reader through the book or journal, once it has been selected. The Institute for Scientific Information publishes a range of Current contents indexes, consisting of reproductions of the contents pages of issues of journals with very basic title keyword indexes to the papers listed on them, and used for current awareness. Some have suggested ways in which the contents pages of books may be used as an extra subject approach in catalogues and indexes. By scanning tables of contents into the bibliographic record, chapter and section headings become available as additional keywords for searching.
Preface and introduction
Where both occur, the precise demarcation line can vary. For the cataloguer, the preface and introduction often provide the author’s own succinct statement of what a book is attempting to achieve.
Back-of-book indexes
Back-of-book indexes provide even more detailed subject information than contents pages, and experimental work has been carried out in using the computer to compile consolidated indexes to a range of books. As with indexes based on contents pages, no commercial systems are yet available.
Publisher’s blurbs
Publisher’s blurbs, if found, are the most eye-catching kind of additional subject information, but should be approached with caution. Their function is to sell the item, not to provide objective information. To that extent they may either represent the subject content as appealing to an implausibly wide range of interest groups or, conversely, focus on an aspect of the content that the publisher hopes will catch the attention. They have, however, been found adequate for the subject indexing of fiction.
In practice, indexers examine sections of the document itself in addition to its preliminaries. The relevant international standard (ISO 5963:1985E), Methods for Examining Documents, Determining their Subjects, and Selecting Indexing Terms, recommends that important parts of the text need to be considered carefully, and particular attention should be paid to the following:
the title
the abstract, if provided
the list of contents
the introduction, the opening phrases of chapters and paragraphs, and the conclusion
illustrations, diagrams, tables and their captions
words or groups of words which are underlined or printed in an unusual typeface.
Summary
The focus of this chapter has been the formatting and structuring of information through documents. We have given an overview of organizing and retrieving information, focusing first on the database and then on the document itself. We have considered some of the problems concerning documents: problems of definition and relationship, and of text analysis; and we concluded with an examination of document markup - instructions facilitating the storage and reuse of electronic documents - and metadata for facilitating access to documents.
References and Further Reading
Buckland, M. K. (1997) What is a ‘document? Journal of the American Society for Information Science, 48 (9), 804–809.
Burke, M. A. (1999) Organization of Multimedia Resources: Principles and Practice of Information Retrieval. Aldershot: Gower.
Dale, P. (ed.) (1997) Guide to Libraries and Information Sources in Medicine and Health Care, 2nd edn. London: British library, Science Reference and Information Services. The Dublin Core Metadata Element Set Home Page <http://www.oclc.org:5046/research/dublin—core/>.
Ford, N. (1991) Expert Systems and Artificial Intelligence. London: Library Association.
Foskett, A. C. (1982) Subject Approach to Information, 4th edn. London: Bingley.
Heery, R. (1996) Review of metadata formats. Program, 30 (4), October, 345–353; (also at <http://www.ukoln.ac.uk/metadata/review>).
International Organization for Standardization (1985) Documentation - Methods for Examining Documents, Determining their Subjects and Selecting Indexing Terms. ISO 5963:1985. Geneva: ISO.
International Organization for Standardization (1986) Information Processing - Text and Office Systems - Standardized Generalized Markup Language (SGML). ISO 8879:1986. Geneva: ISO.
Kunze, J. Guide to Creating Dublin Core Descriptive Metadata <http://purl.oclc.org/metadata/dublin_core/guide.>.
Meadow, C. T. (1996) Text Information Retrieval Systems. San Diego: Academic Press, (especially chapters 1, 2 and 3).
Mostafa, J. (1994) Digital image representation and access. Annual Review of Information Science and Technology; 29, 91–135.
Rasmussen, E. M. (1997) Indexing images. Annual Review of Information Science and Technology; 32, 169–196.
Schamber, L. (1996) What is a document? Rethinking the concept in uneasy times. Journal of the American Society for Information Science, 47 (9), September, 669–671.
Tillett, B. B. (1991) A taxonomy of bibliographic relationships. Library Resources and Technical Services, 35 (2), 150–158.
Vellucci, S. L. (1997) Options for organizing electronic resources: the coexistence of metadata. Bulletin of the American Society for Information Science, 24 (1) October-November, 14–17.
Vellucci, S. L. (1998) Bibliographic relationships. In J. Weihs, (ed.), The Principles and Future of AACR: Proceeding? of the International Conference on the Principles and Future Development ofAACR, Toronto, Ontario, Canada, October 23–25, 1997. Ottawa: Canadian Library Association, 105–147.
Vickery, B. C. (1997) Knowledge discovery from databases: an introductory review. Journal of Documentation, 53 (2), 107–122.
Weibel, S. (1997) The Dublin Core: a simple content description model for electronic resources. Bulletin of the American Society; 24 (1), October-November, 9–11.
Weihs, J. (ed.) (1998) The Principles and Future ofAACR: Proceedings of the International Conference on the Principles and Future Development of AACR2, Toronto, Ontario, Canada, October 23–25, 1997. Ottawa: Canadian Library Association. For later developments, see the Joint Steering Committee’s Web site: <http://www.nlc-bnc.ca/jsc/index.htm>.